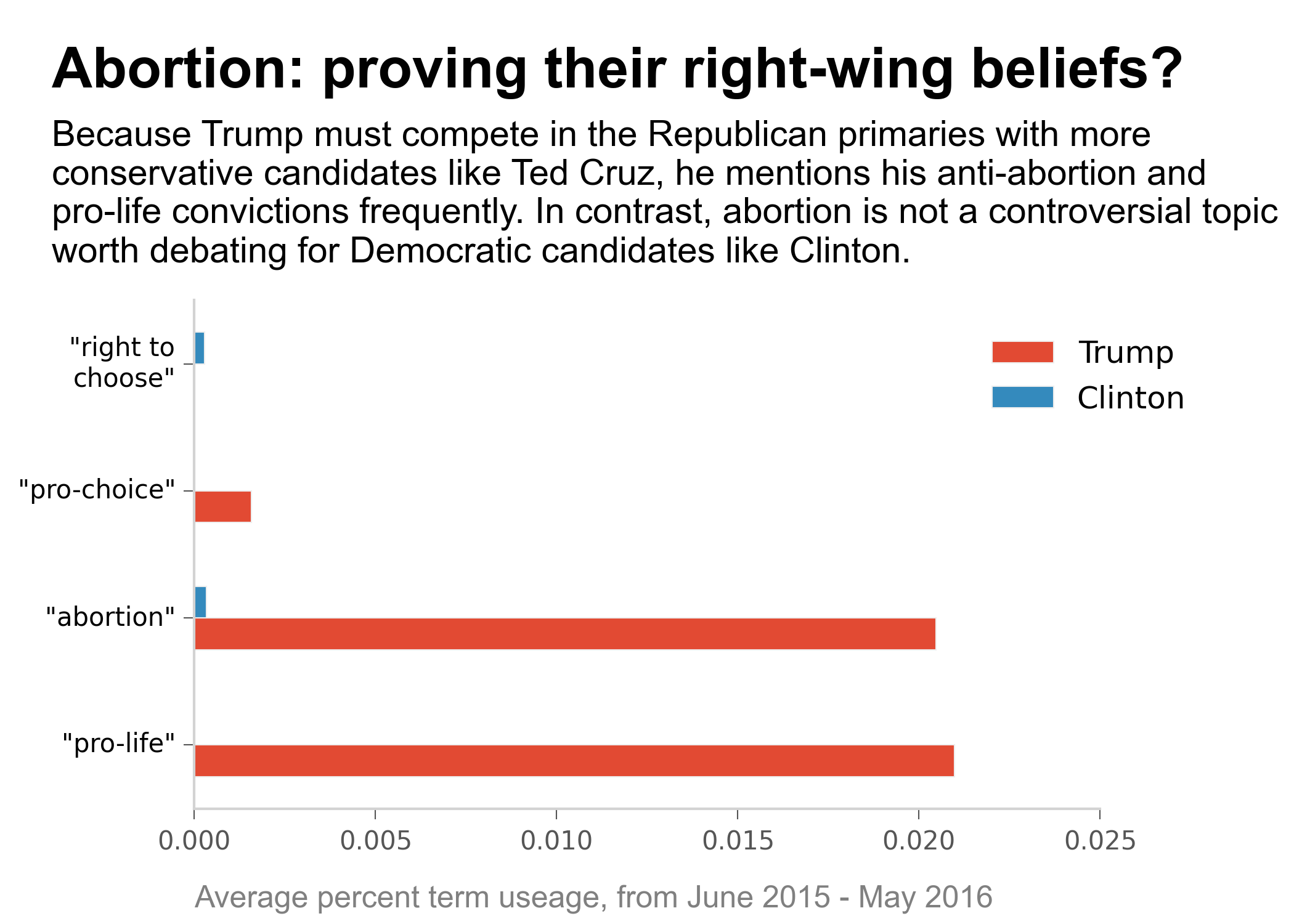
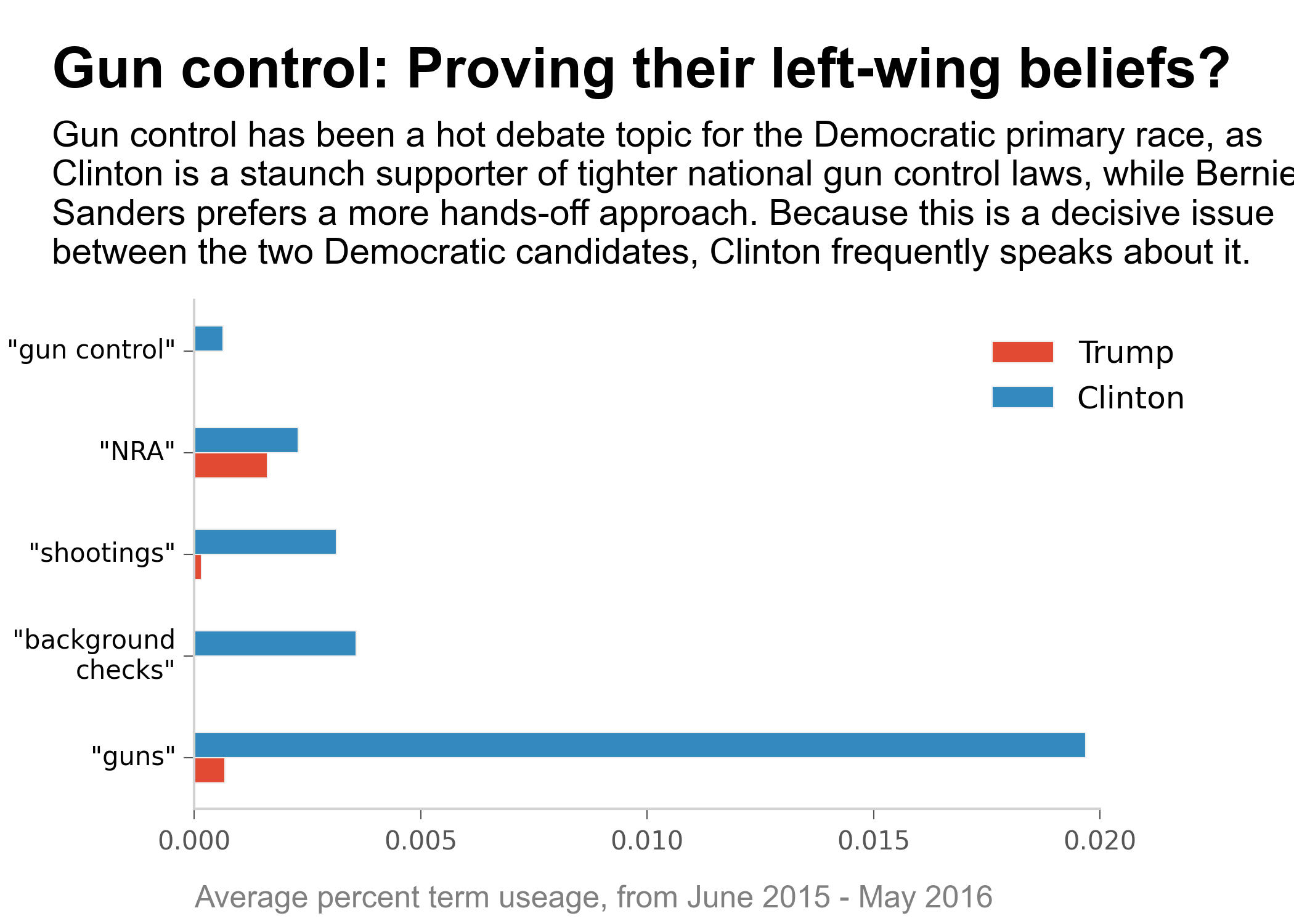
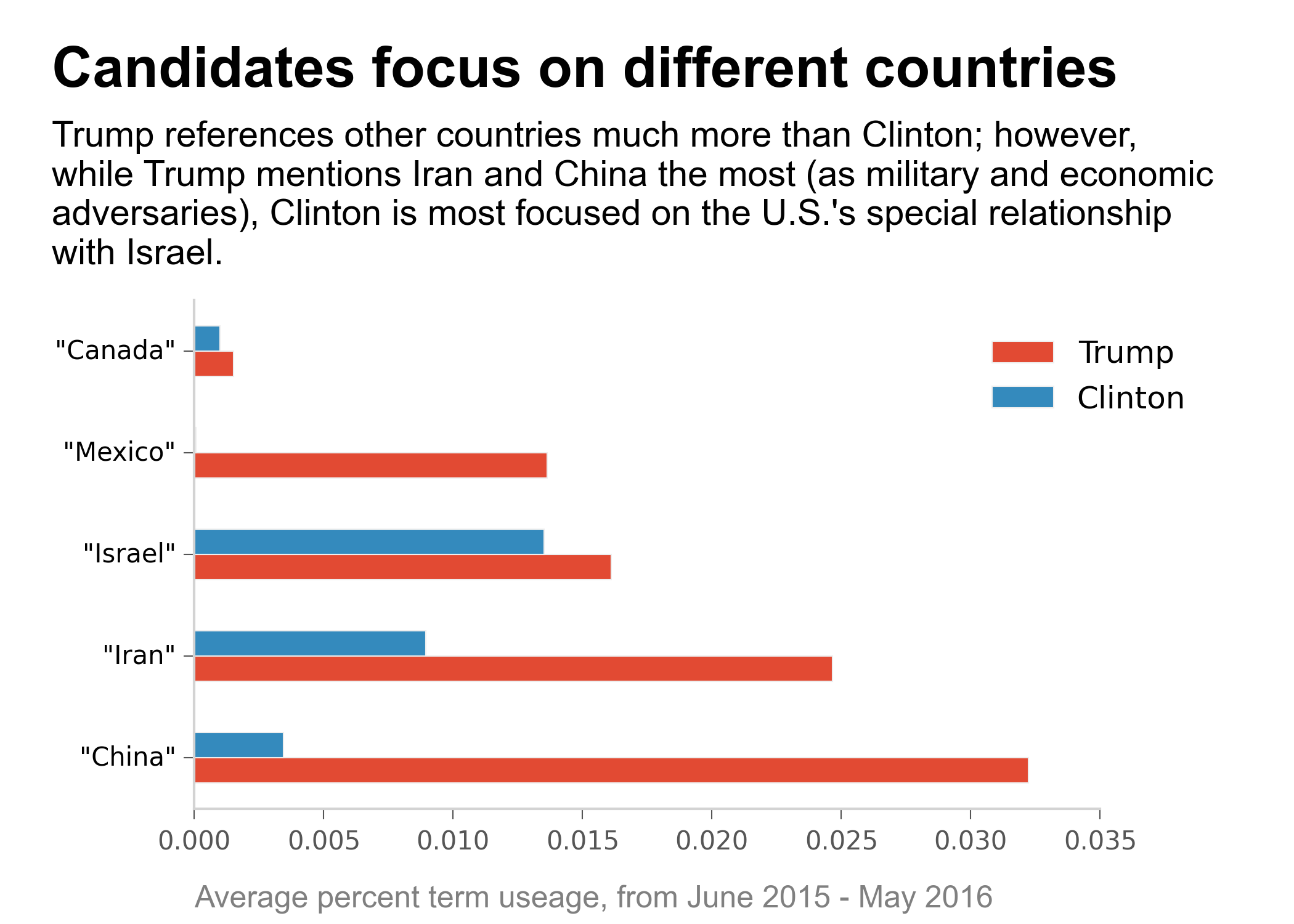
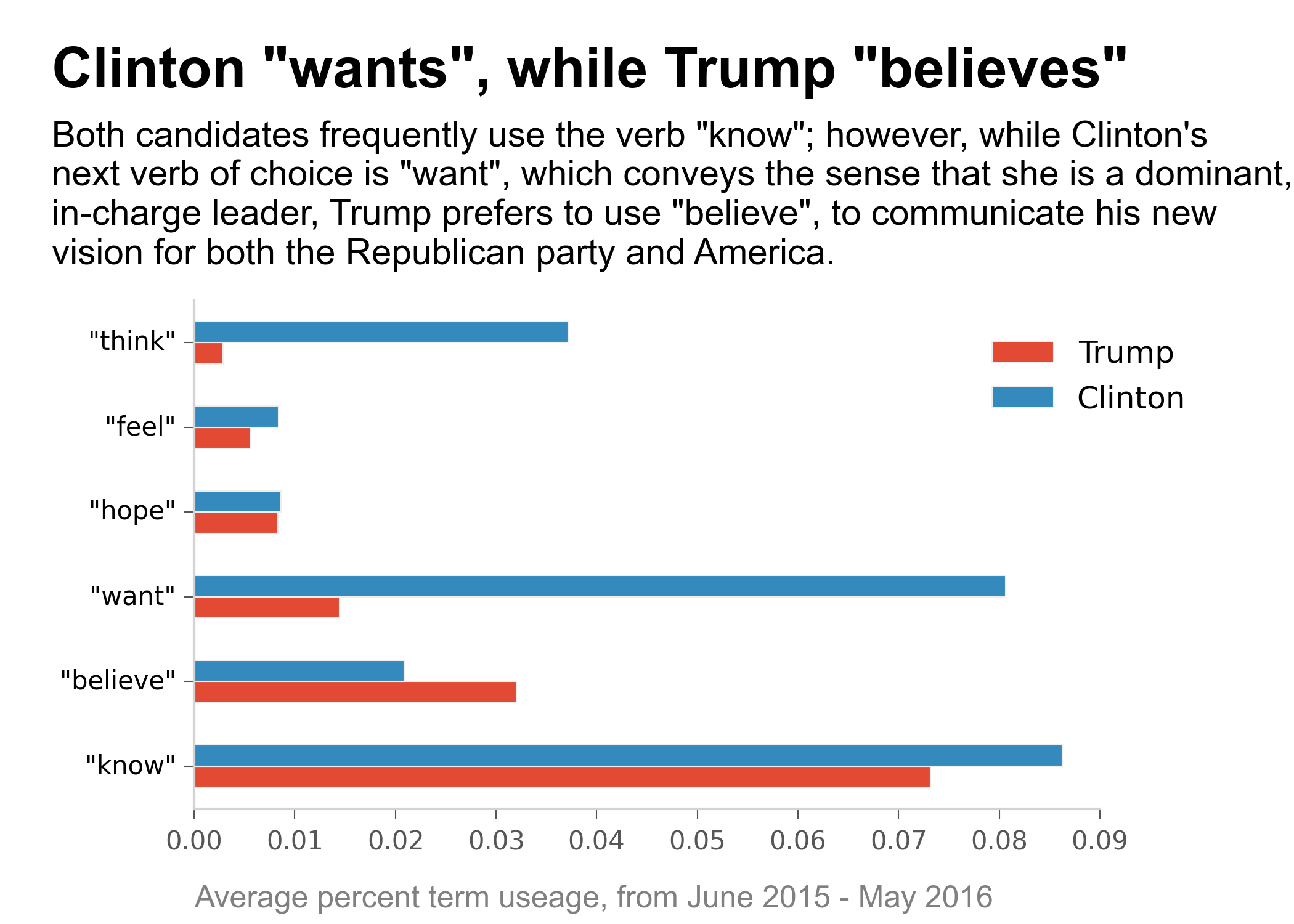
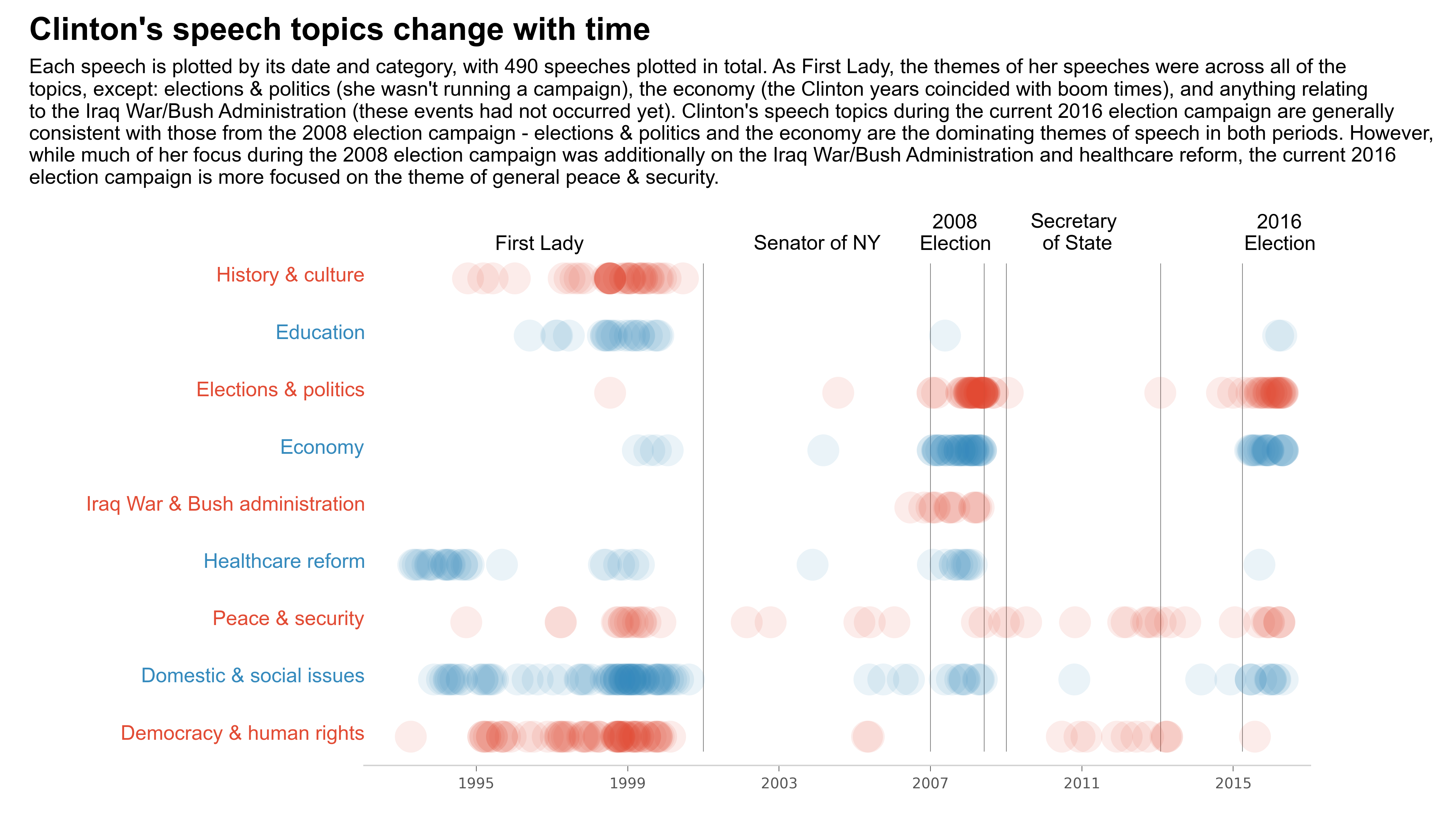
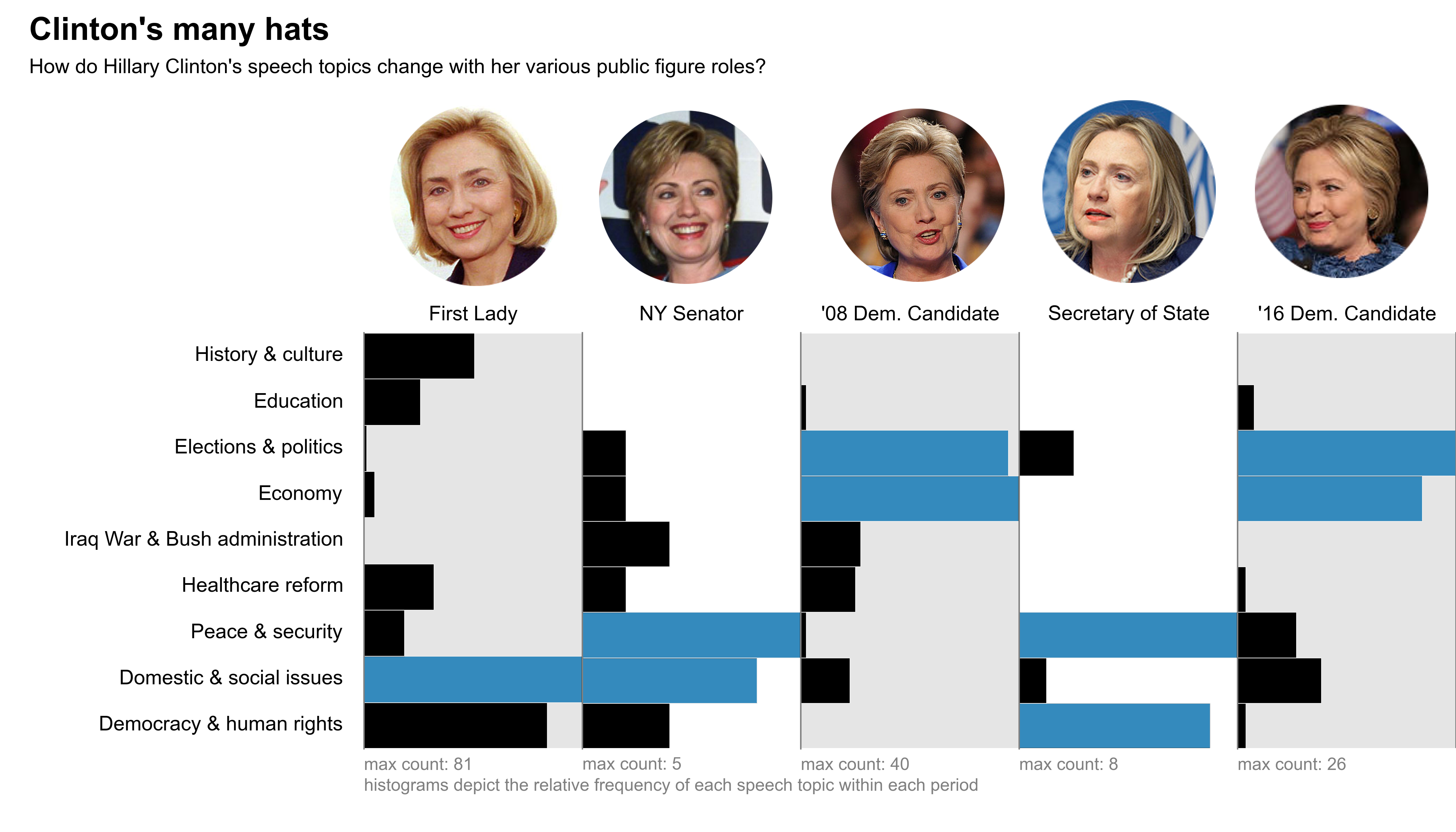
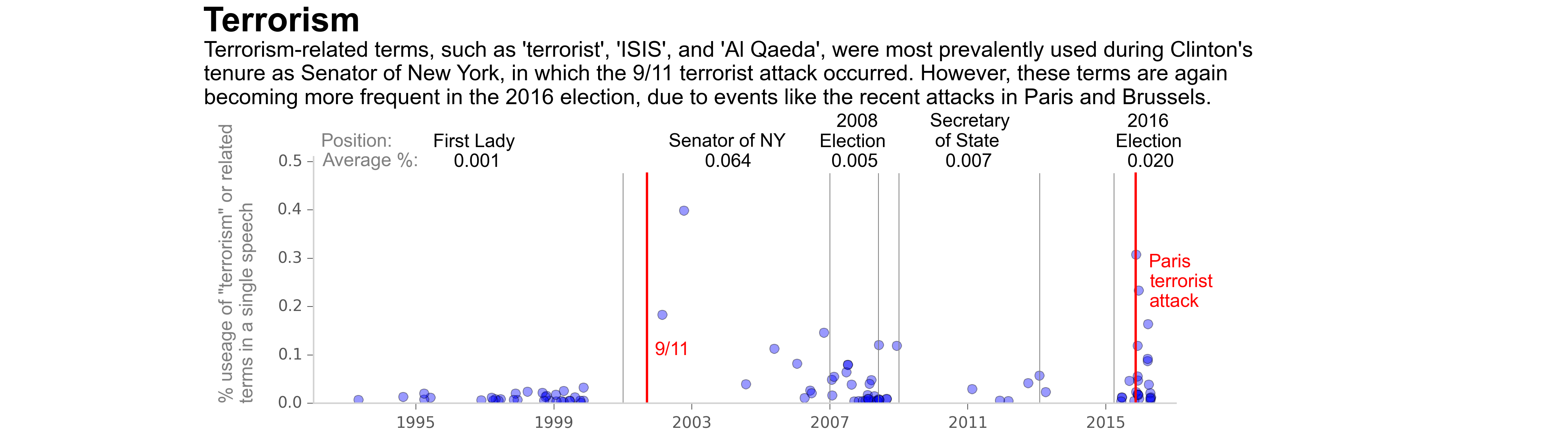
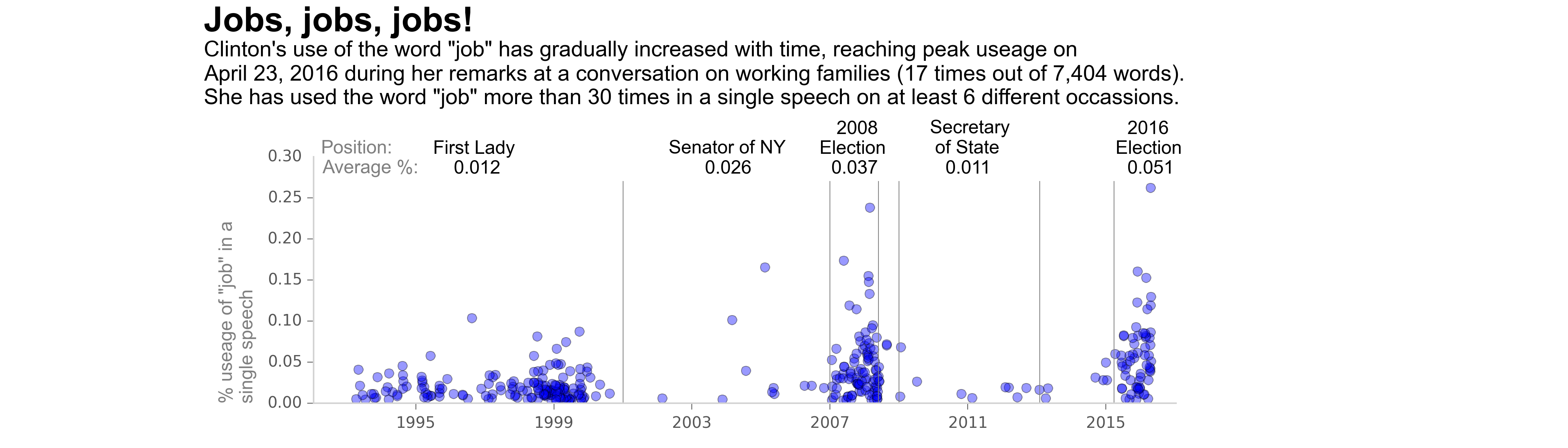
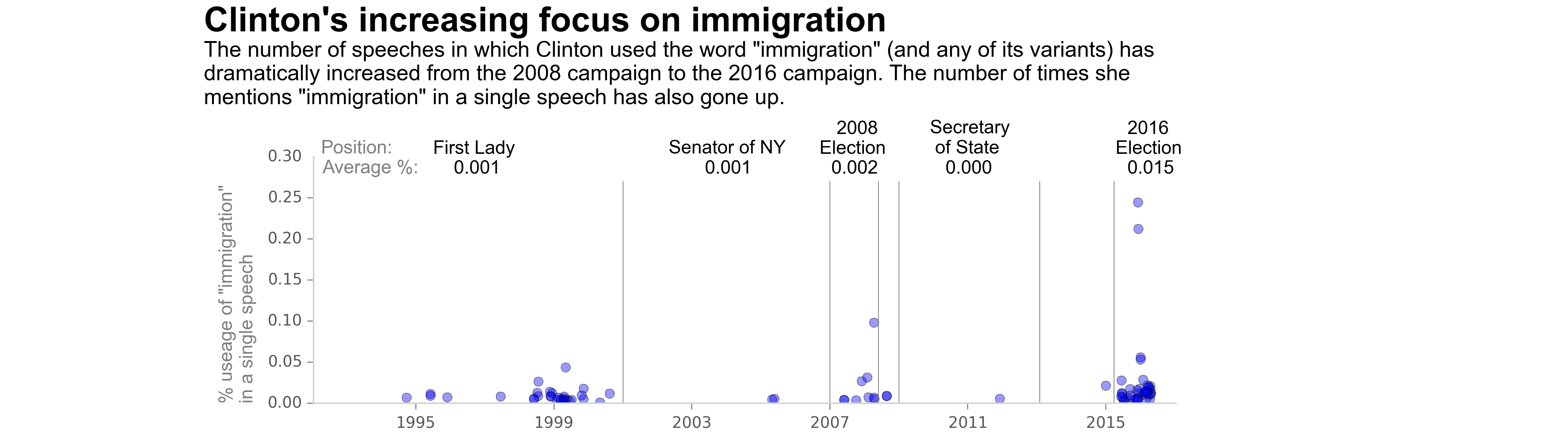
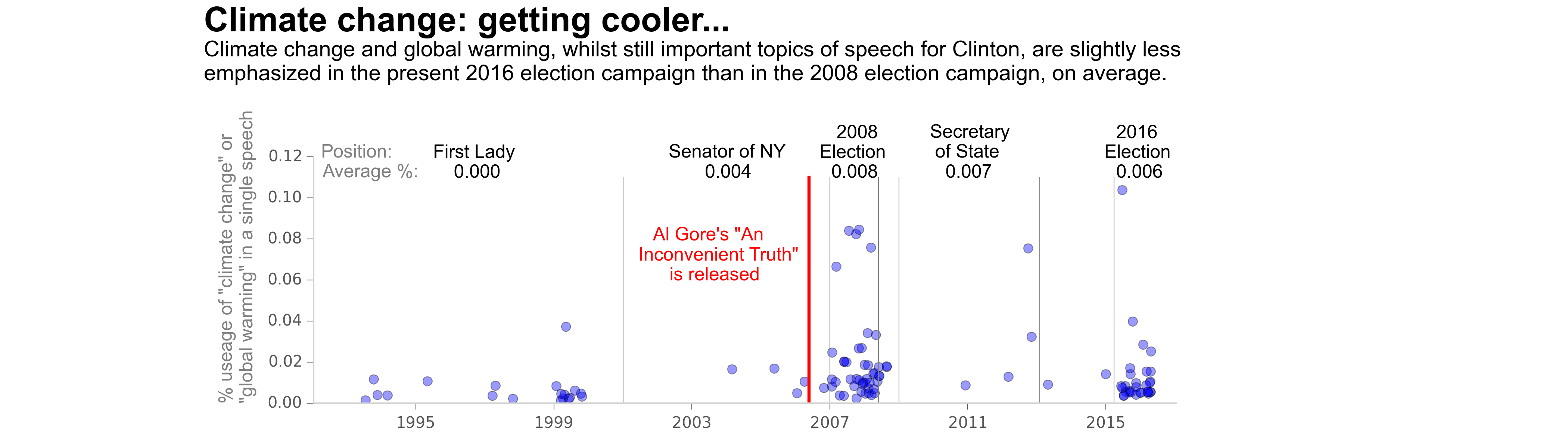
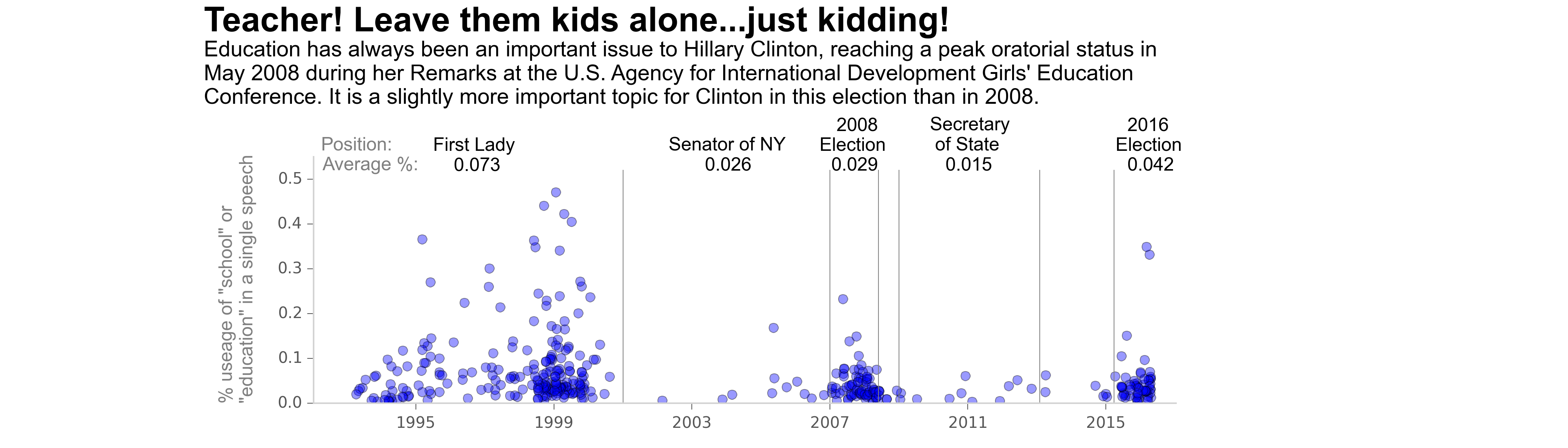
Candidates' Speech Analysis Project
No matter what we talk about, we are talking about ourselves.
- author Hugh Prather
What people say is important. We remember people by the famous words they said, whether it be Martin Luther King Jr.'s "I have a dream", to J.F.K.'s, "Ask not what your country can do for you - ask what you can do for your country." In this day and age, what people say is even more important as everything can be recorded and archived indefinitely.
Analyzing every aspect of a politian's way of speaking is a popular hobby these days. From way back in 2007, when then-Senator Barack Obama was celebrated for his deep and resonant Smoker's voice", to the present day's countless articles attacking or defending Hillary Clinton purely on the basis of her speaking tone, Americans are obsessed with the way our leaders talk.
These previous analyses have only been qualitative. Now, however, we can start taking apart the 2016 POTUS candidates' speech patterns based on quantitative metrics. For example, the Wall Street Journal's article, What Speech Patterns Say About the Presidential Candidates, looked at how many unique words they use, on average, and what the total number of words spoken was:
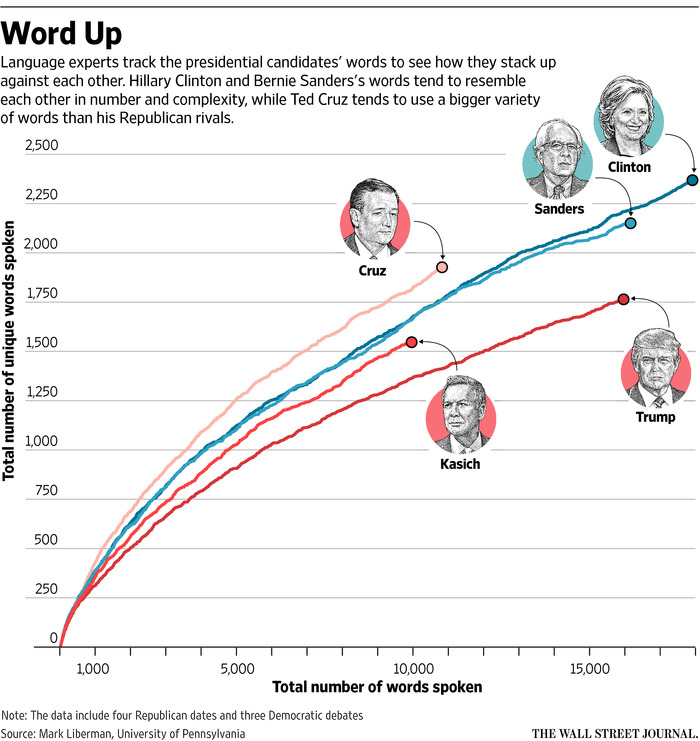
Similarly, the New York Times recent article, Ted Cruz as Beowulf: Matching Candidates With the Books They Sound Like, examined which books each candidates' speech patterns most likely resemble, based on quantifying their speaking styles as complex (e.g. Beowulf) or simple (e.g. Adventures of Huckleberry Finn), and negative (e.g. Ulysses") or positive (e.g. The Divine Comedy: Paradise):
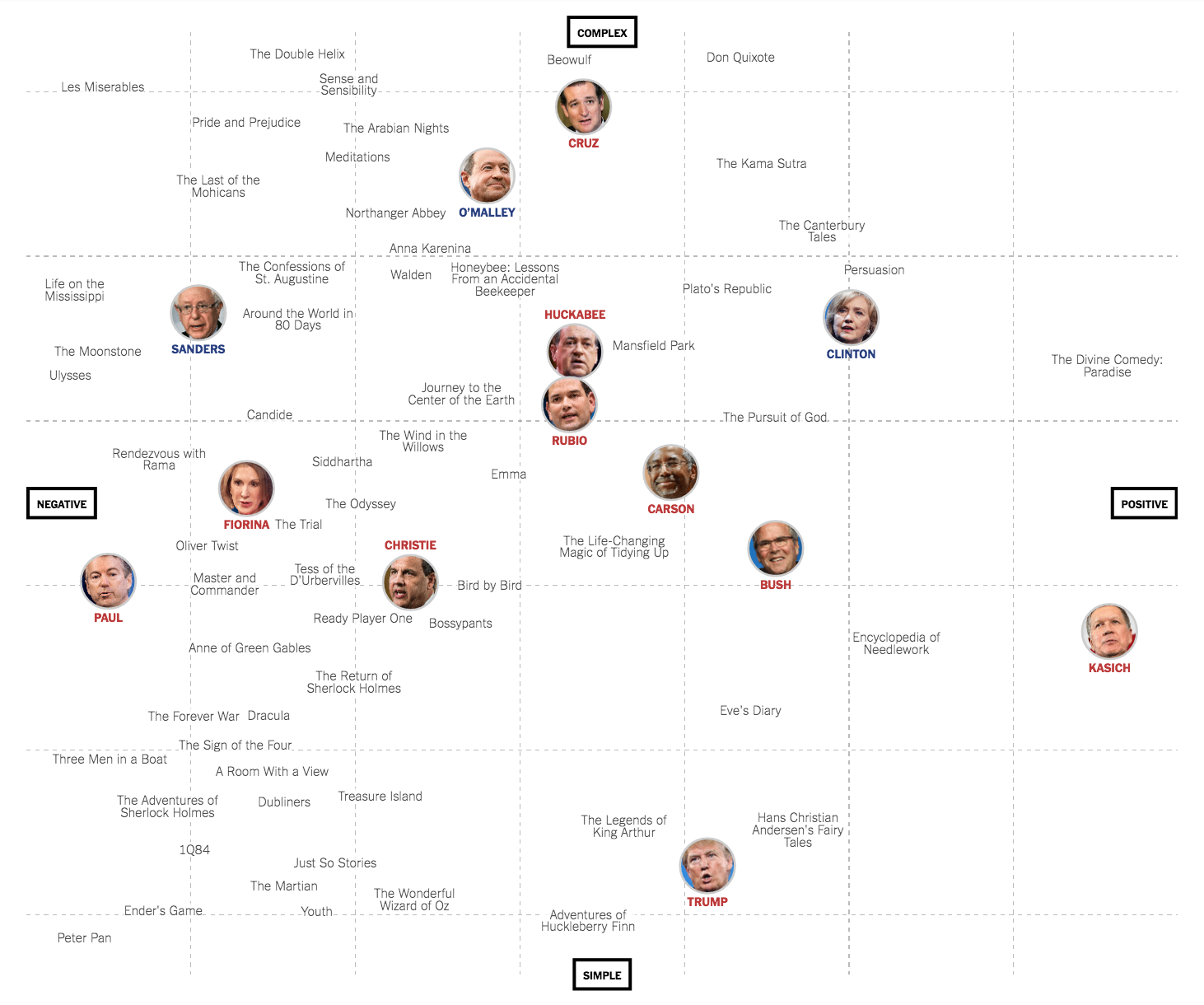
Interestingly, while the above analysis found Donald Trump to have relatively positive speech patterns, a different article by the New York Times found the leading Republican candidate to have an "ominous" tone, with "constant repetition of divisive phrases, harsh words and violent imagery."
Such analyses of speech patterns remain incredibly popular and compelling to the general public. The New York Times article on Trump's ominous speaking style garnered 1,392 comments. The above Wall Street Journal article had 1,229 Facebook likes. With almost two dozen televised debates and countless more interviews and speeches, it makes sense to put a magnifying glass to the plethora of words spilling from the candidates' mouths.